Das 5-Stufen-Modell in LogNetz
Vom Einzelkämpfer zum Netzwerk-Player - Alle wichtigen Begrifflichkeiten zu Wertschöpfungsnetzwerken sind hier zusammengefasst
LogNetz 5-Stufen Modell

Inhaltsübersicht
- Stufe 1: Datenqualität und -verfügbarkeit
- Stufe 2: Netzwerk - Struktur
- Stufe 3: Bestände und Flüsse im Netzwerk
- Stufe 4: Performance
- Stufe 5: Optimierung
- Literatur
Stufe 1: Datenqualität und -verfügbarkeit
Datentypen in der Supply-Chain
Valide und verfügbare Daten sind Grundlage für Planung, Analyse und Implementierung einer Logistik-Lieferkette. In einer typischen datengesteuerten Supply-Chain-Struktur wird die Nachfrage auf Kundenseite initiiert, welche durch nachfolgende Stufen zum Lieferantenende umgesetzt wird. Die Lieferung von Waren und Dienstleistungen folgt dem Weg vom Lieferanten zum Kunden. Die Rücksendung von Waren zur Reparatur, Wiederaufarbeitung und zum Recycling erfolgt auf dem umgekehrten Weg zur Nachfrage [1].
![Abbildung 1: Architektur für Big-Data-getriebene Supply-Chain-Analytik (Quelle: [1])](/storage/app/media/uploaded-files/Bild1.png)
Abbildung 1: Architektur für Big-Data-getriebene Supply-Chain-Analytik (Quelle: [1])
Die hierbei anfallenden Daten können grob in vier Kategorien eingeteilt werden [1]:
- Lieferantendaten fallen im Zusammenhang mit dem Beschaffungsprozess an. Beispiel sind Konstruktionsdaten, Auftragsstatus, Lagerbestand, Zeitplan, Versand & Weiterleitung, Rückgabe / Entsorgung, Finanzdaten, Location
- Herstellungsdaten werden aus den vom Hersteller durchgeführten Bearbeitungsaktivitäten generiert. Beispiele sind: Aktivitätsdaten, Konstruktionsdaten, Vorhersagedaten, Produktionsplan, Kapazitätsplan, Prozessdaten, Ertragsdaten, Qualitätsdaten, Lagerbestand, Wartungsaufzeichnungen, Kundenfeedback, Lieferantendaten, Finanzdaten, Rückgabe / Entsorgung, Location
- Lieferdaten fallen an, wenn das Produkt an das Lager geliefert und an die Endkunden verteilt wird. Beispiele sind: Nachfrage, Lagerbestand, Zeitplan, Versand & Weiterleitung, Bestellung, Rückgabe / Entsorgung, Kundenfeedback, Location
- Verkaufs- und Vertriebsdaten enthalten Kundeninformationen zu Umsatz und Produktnachfrage. Beispiele sind: Verkaufsstelle, Bestellstatus, Nachfrage, Produktrückmeldungen, Kundenrückmeldungen, Zahlung, Lieferung, neues Produkt, Werbeaktionen / Empfehlungen, Rückgabe / Entsorgung
Datenqualität
Ergebnisse und Werte einer Datenanalyse hängen stark von der Qualität und Menge der Eingabedaten ab. Um verlässliche Ergebnisse zu erzielen, muss zu Beginn die Qualität der Daten sichergestellt werden. Die folgenden Parameter können zur Qualitätsabschätzung verwendet werden [2, 3]:
- Data Volume/ Datenvolumen (Vol)
Größe der zu analysierenden und zu verarbeitenden Datensätze (mittlerweile im Terabyte- oder Petabyte-Breich). Das schiere Datenvolumen (Stichwort: Big Data) erfordert andere Verarbeitungstechnologien als herkömmliche, vom heimischen Laptop gewohnte Speicher- und Verarbeitungsfunktionen. - Data Variety/Datenvarietät (Var)
Daten können in strukturierter, halbstrukturierter oder unstrukturierter Form vorliegen. Die sich daraus ergebende Vielzahl der Datentypen erfordert häufig unterschiedliche Verarbeitungsfunktionen und spezielle Algorithmen. - Data Security and Privacy/Datensicherheit und Datenschutz (SecPri)
Bewerten Sicherheit und den Datenschutz der jeweiligen Big Data-Datensätze aus verschiedenen Perspektiven. Dieser Qualitätsfaktor ist für Big Data-Analysedienste, aber auch für das Veröffentlichen und Teilen von Big Data von Bedeutung. - Data Completeness/Datenvollständigkeit (Com)
Misst die Vollständigkeit großer Datenmengen innerhalb einer ausgewählten Domäne. Anhand dessen wird bewertet, wie viele gültige Analysedaten im Vergleich zu der geplanten Menge erhalten wurden. Die Vollständigkeit der Daten wird normalerweise als Prozentsatz der verwendbaren Analysedaten ausgedrückt. - Data Accessibility/Datenzugang (Acce)
Wie einfach ist der Zugriff für Unternehmen und öffentliche Benutzer auf einen bestimmten Big-Data-Datensatz. - Data Accountability/Datenverantwortlichkeit (Acco)
Big-Data-Verantwortlichkeiten können auf unterschiedliche Weise definiert und bewertet werden, beispielsweise Verantwortlichkeiten für- Datenerfassung und Vorverarbeitung,
- Datenverwaltung und -verarbeitung,
- oder Analytics-Anwendungsdienste.
Eine klare Verantwortlichkeitszuweisung ist für Big-Data-Dienstanwendungen wie auch für den Benutzer sehr wichtig und obligatorisch. Dieser Faktor ist ein kritischer Erfolgsindikator für jeden Big-Data-Anbieter.
- Data Scalability/Skalierbarkeit von Daten (Sca)
Bewertet, wie gut Big Data strukturiert, entworfen, gesammelt, generiert, gespeichert und verwaltet wird, damit für bestimmte Arbeiten auf den Daten (Transport, Migration, Analyse) die Datenerfassung und der Zugriff auf die Daten funktioniert.
Data Analytics
Die Lieferkette produziert riesige Datenmengen. Datenanalysen werden verwendet, um diese Daten in wertvolle Informationen umzuwandeln, mit denen das Unternehmen seinen Betrieb verbessern sowie strategisch planen kann.
Es gibt drei Analyseebenen, deskriptive, prädiktive und präskriptive, die abhängig von Verfügbarkeit und Qualität der Daten sowie Komplexität der Systeme separat oder zusammen angewandt werden können. Die Abbildung zeigt die Anwendbarkeit der drei Ebenen in Bezug auf die Informationsmenge und die Komplexität.
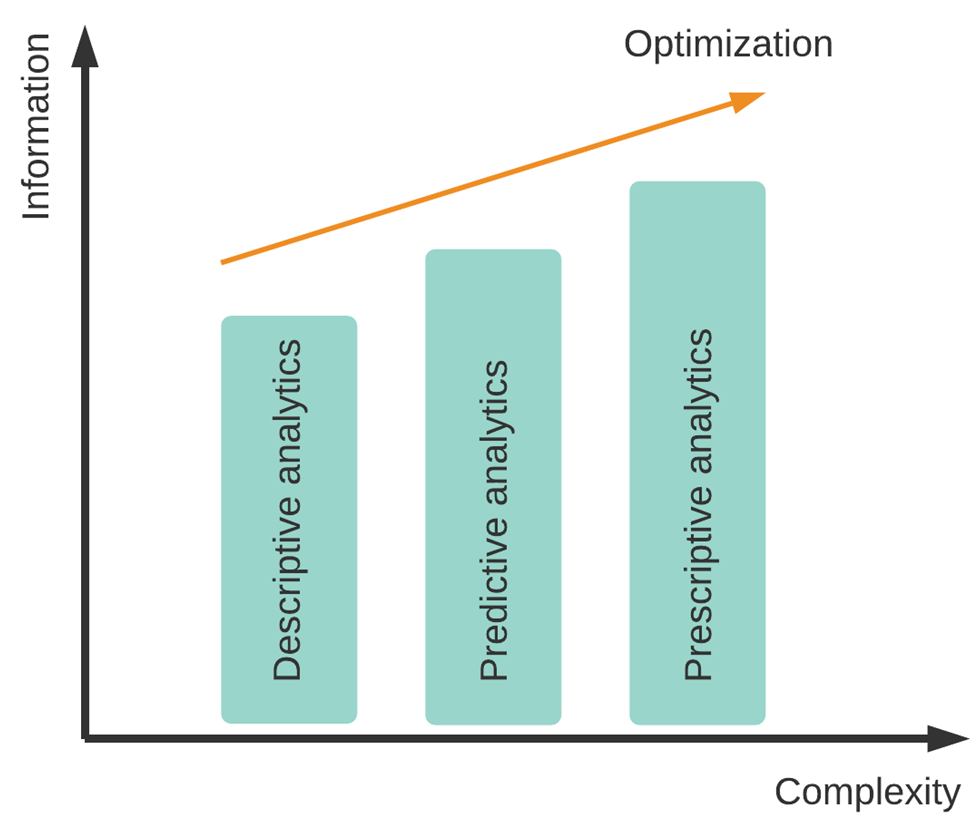
Abbildung 2: Analyseebenen
- Descriptive Analytics / Deskriptive Analyse beantwortet die Frage "Was ist passiert?".
Aus dem Geschehen der Vergangenheit erhalten Unternehmen aufschlussreichere Informationen, um ihre Organisation besser zu verstehen. Die Analyse schafft Transparenz und ermöglicht eine realistische Darstellung der gesamten Lieferkette für interne und externe Systeme und Daten [4]. - Predictive Analytics / Prediktive Analyse beantwortet die Frage "Was wird passieren?".
Es werden Informationen aus der Vergangenheit verwendet, um die Zukunft vorherzusagen. Dies hilft den Unternehmen, sich besser auf zukünftige Szenarien vorzubereiten, indem wahrscheinliche Ergebnisse oder zukünftige Szenarien und seine geschäftlichen Auswirkungen ermittelt und vor allem erklärbar werden. Beispielsweise können Störungen und Risiken vorausberechnet und dadurch gemindert werden [4]. - Prescriptive Analytics / Präskriptive Analyse beantwortet die Frage "Wie können wir das erreichen?".
Sie zeigt Unternehmen Wege auf, im Sinne einer strategischen Ausrichtung heute Entscheidungen zu treffen, die bestimmte Unternehmensziele (bspw. Gewinnmaximierung) in der Zukunft erreichen lassen. Durch die aufgezeigten Problemlösungswege können Geschäftsvorteile maximiert werden, beispielsweise bei der Zusammenarbeit mit Logistikpartnern, um Zeit und Aufwand bei der Minderung von Störungen zu reduzieren [4].
Stufe 2: Netzwerk - Struktur
In der Stufe „Netzwerk – Struktur“ geht es um das Aufzeigen des Wertschöpfungsnetzwerkes, also die Verknüpfungen des Unternehmens mit seinen direkten und indirekten Stakeholdern (z.B. Kunden, Lieferanten, Distributoren). Es wird der Ist-Zustand des Supply Chain Netzwerkes betrachtet. Dadurch können beispielsweise kritische Lieferanten identifiziert oder durch die Visualisierung auf einer Karte übersichtlich aufgezeigt werden.
Wertschöpfungsnetzwerk (Supply Chain Network)
Die Struktur, die sich aus den Beziehungen der beteiligten Wertschöpfungspartner ergibt, wird in diesem Projekt als Netzwerk betrachtet („Wertschöpfungsnetzwerk“). Diese Netzwerkstruktur ist im Supply Chain Management Modell von [5] bereits angedeutet (siehe nachfolgende Abbildung). In der Praxis betrachtet jedes Unternehmen das Netzwerk aus dem eigenen Standpunkt (fokales Unternehmen). Der Netzwerkabschnitt, der die Lieferanten umfasst, wird als Lieferanten- beziehungsweise Zuliefernetzwerk bezeichnet („upstream“), der Abschnitt, welcher die Kunden enthält, als das Distributionsnetzwerk („downstream“).
![Abbildung 3: Supply Chain Management Modell (Quelle: [5], bearbeitet von [6])](/storage/app/media/uploaded-files/Bild3.png)
Als Grundlage dient eine Darstellung des Netzwerkes durch eine bestimmte Anzahl an Knoten (Akteure) sowie die Menge der zwischen diesen verlaufenden Kanten (Verbindungen). [7–11]
Bei den Knoten kann es sich um
- Individuen,
- ein einzelnes Unternehmen,
- eine beliebige Anzahl von Organisationen,
- Gruppen oder
- Gesellschaften handeln.
Die Kanten können in die Kategorien
- Inhalt (zum Beispiel Transaktionen, Materialfluss, Information, Kommunikation, Emotion, physische oder soziale Bewegung),
- Form (zum Beispiel Dauer oder Enge der Bindung) und
- Intensität (zum Beispiel Häufigkeit der Interaktion)
eingeordnet werden. [9, 10, 12]
Supply Chain vs. Supply Network
Wertschöpfungsnetzwerke (Supply Networks) sind in größere organisationsübergreifende Netzwerke eingebettet und bestehen aus miteinander verbundenen Einheiten, deren Hauptzweck die Beschaffung, Nutzung und Umwandlung von Ressourcen zur Bereitstellung von Waren- und Dienstleistungspaketen ist. Diese Netzwerke umfassen Ketten (Supply Chains), durch die Waren und Dienstleistungen von den ursprünglichen Lieferquellen zu den Endkunden fließen. [13]
Das Konzept des Wertschöpfungsnetzwerkes beschreibt somit Entitäten auf mehreren Wertschöpfungsstufen, die miteinander in Verbindung stehen und an der Herstellung eines Produktes von der Bezugsquelle bis zur Verbrauchsstelle beteiligt sind. Durch die steigende Anzahl an Unternehmen im Herstellungsprozess und dem damit verbundenen Anstieg der Komplexität, ist das Netzwerk-Konzept (Supply Network) geeigneter als jenes der Kette (Supply Chain), um die nicht linearen und dynamischen Beziehungen zwischen Unternehmen zu beschreiben. Zu jedem Unternehmen bestehen Verbindungen, die entweder direkt oder über weitere Unternehmen indirekt zustande kommen. Die Steuerung und Kontrolle dieser Verbindungen wird als Supply Chain Management bezeichnet. [6] In der nachfolgenden Tabelle wird gegenübergestellt, wie sich die Betrachtung der Supply Chain als eine „Kette“ und als ein „Netzwerk“ in einigen Dimensionen unterscheiden.
| Dimension | Supply Chain | Supply Netzwerk |
|---|---|---|
| Fokales Konzept | Produkte / Dienstleistungen | Beziehungen |
| Design / Konfiguration | Lineare, relativ stabile Strukturen | nichtlineare, dynamische Strukturen |
| Komplexität | gering | hoch |
| Operationen | vorhersehbar / stabil | nicht vorhersehbar / instabil |
| Koordination | Fokus auf die Koordination von Material-, Informations- und Finanzfluss sowie Integration | Fokus auf die Koordination der zwischenbetrieblichen Beziehungen |
| Integration | strukturiert | spontan / ungeplant |
Tabelle 1: Gegenüberstellung Supply Chain und Supply Netzwerk (Quelle: [14], bearbeitet von [6])
Analyse des Wertschöpfungsnetzwerkes (Supply Chain Network Analysis)
Neben der Performance der einzelnen Partner (Knoten) spiel auch die Struktur des Netzwerkes eine Rolle für die Gesamtleistung („Netzwerktheorie“). Einerseits hat die Einbettung („embeddedness“) und andererseits haben die Flüsse („flows“) im Netzwerk maßgebliche Auswirkung auf die Performance des Netzwerks. [14]
Um die Netzwerkstruktur eines fokalen Unternehmens analysieren zu können, müssen gewisse Aspekte berücksichtigt werden [15, 16]:
- Identifikation aller Netzwerkakteure, mit welchen das fokale Unternehmen direkt oder indirekt Geschäfte führt (Kunden- und Lieferantenseite),
- die Netzwerkdimension, die die Anzahl der Wertschöpfungsstufen, Akteure je Stufe und die Position des fokalen Unternehmens beschreibt,
- die Arten der Geschäftsprozesse,
- der Grad mit welchem die Partner des fokalen Unternehmens miteinander verknüpft sind.
Auf dieser Basis können anschließend Analysen durchgeführt werden. Die Soziale Netzwerkanalyse (Social Network Analysis) bietet Methoden, um Aussagen über die Netzwerkstruktur und über einzelne Knoten im Netzwerk treffen zu können. Es gibt unterschiedliche Maßzahlen, die jeweils verschiedene Aspekte der Einbettung eines Knotens in ein Netzwerk erfassen. Zum Beispiel können Geschäftsbeziehungen und Unternehmen aufgrund ihrer Verbindungen zu anderen kritischen Unternehmen selbst kritisch sein („eigenvector centrality“), sie können wichtige Materialflüsse kontrollieren („betweenness centrality“) oder sie können eine große betriebliche Belastung haben („degree centrality“) [11, 17].
Die „Nexus Supplier“ Theorie nach [18] integriert soziale Netzwerkanalyse mit Supply Management und zielt darauf ab, kritische Lieferanten anhand ihrer Position und Lage zu anderen Unternehmen im Netzwerk zu identifizieren. Diese Identifikation ist wichtig, da die Performance des untersuchten Unternehmens maßgeblich beeinflusst werden kann. Da Nexus Lieferanten üblicherweise nur indirekt mit der fokalen Firma verbunden sind, sind diese für das Supply Chain Management schwierig zu erfassen. Hier kann die Soziale Netzwerkanalyse einen Beitrag leisten, um Risiken zu minimieren. [18, 19]
Umfassende Netzwerkanalysen können auch dabei helfen eine Entscheidung zu treffen, ob ein potenzieller Unternehmenspartner geeignet ist. Durch das Aufzeigen der Netzwerkstruktur und der Bewertung jedes Unternehmens im Netzwerk, können Maßnahmen für eine weitere positive Entwicklung gesetzt werden.
Alle weiteren Stufen des Projektprogrammes beinhalten ebenso Analysen, auf deren Basis Entscheidungen unterstützt werden können (z.B. Bestandsanalysen, KPIs, Operations Research, Optimierung, Prognosemodelle).
Stufe 3: Bestände und Flüsse im Netzwerk
Einfache Fragen, die sich mit beschreibender Statistik beantworten lassen, sind:
- Wie hoch sind die Bestände an gewissen Knoten zu bestimmten Zeitpunkten?
- Welche Mengen fließen zu bestimmten Zeitpunkten über gewisse Kanten des Netzwerkes?
Darauf aufbauend stellt sich die Frage, wie sich diese Bestandsmengen und Flussmengen im Laufe der Zeit entwickeln. Hierzu können historische Daten genutzt werden, um beispielsweise zeitliche Verläufe darzustellen, oder um Zusammenhänge von Ereignissen zu untersuchen.
Wertschöpfungsnetzwerke sind komplexe Systeme, die mehrere Stufen enthalten, welche die Aktivitäten der Warenbewegung und Wertschöpfung von der Rohstoff- bis zur Endauslieferungsphase umfassen. In diesen Netzwerken gibt es verschiedene Arten von Unsicherheiten, z.B. Nachfrageunsicherheit, Produktionsunsicherheit und Lieferunsicherheit. Entscheidungen darüber, wie viel und wann nachgeliefert werden soll, beinhalten oft einen Rückkopplungsprozess, der eine Interaktion zwischen den Systemeinheiten auslöst, was zu schwer vorhersehbarem Verhalten des Systems führen kann. Zwischen dem Zeitpunkt, an dem eine Entscheidung getroffen wird und jenem, an dem deren Wirkung spürbar wird, besteht in der Regel eine Zeitverzögerung, die die Interaktion zwischen den Stufen meist noch komplizierter macht. Rückkopplung, Interaktion und Zeitverzögerung treten in vielen Prozessen von Wertschöpfungsnetzwerken auf, was diese zu dynamischen Systemen macht (Supply Chain Dynamics) [20]. Daraus ergeben sich Fragestellungen wie zum Beispiel:
- Führt ein kritischer (z.B. zu niedriger) Bestand Upstream zu kritischen Beständen Downstream?
- Wie schnell und wie weit verbreitet sich diese Kritikalität im Netzwerk?
- Kann eine Verspätung auf einer Teilstrecke des Netzwerkes auf der Reststrecke aufgeholt werden?
- Wie weit wirkt sich ein Problem (z.B. Wartungsarbeiten in einer Produktion, die zu Zeitverzögerungen führen) im restlichen Netzwerk aus? Beeinflusst es auch andere Produkte als jenes, der betreffenden Produktion?
Diese Fragen führen zum Themenfeld „Supply Chain Risk Propagation“, in dem die Verbreitung von Risiken untersucht wird. Störungen in Wertschöpfungsnetzwerken können unterteilt werden in häufige Ereignisse mit geringer Auswirkung (operative Risiken) und seltene mit großer Auswirkung (disruptive Risiken). Der ersten Kategorie kann der sogenannte „Bullwhip-Effekt“ zugeordnet werden. Der zweiten Kategorie wird beispielsweise der „Ripple-Effekt“ zugeordnet. Das Verhalten und die Entwicklung von Beständen und Flüssen (Material, Information, Geld) im Netzwerk kann mit unterschiedlichen Theorien beschrieben werden.
Supply Chain Risikomanagement
Die Risiken der Supply Chain werden unternehmensübergreifend analysiert. Das Supply Chain Risikomanagement (kurz: SCRM) ist die Schnittstelle der beiden Forschungsfelder Supply Chain Management und Risikomanagement, wodurch in modifizierter Weise Methoden aus beiden Bereichen angewandt werden können. Um ein erfolgreiches Risikomanagement aufbauen zu können, gilt es:
- Risiken zu identifizieren,
- deren Eintrittswahrscheinlichkeiten zu berechnen und die einzelnen Risiken zu bewerten,
- eine effiziente Risikosteuerung zu etablieren
- und eine Risikokontrolle durchzuführen.
Da sich die einzelnen Lieferketten der Unternehmen stark unterscheiden können, sind vor allem die gemeinsamen Ziele und eine gemeinsame Risikostrategie von hoher Bedeutung bei der Steuerung von potenziellen Störungen auf den Material- und Informationsfluss einer Supply Chain. [21–23]
Operative vs. disruptive Risiken
Operative Risiken äußern sich in Schwankungen der Nachfrage oder Durchlaufzeiten [24]. Es handelt sich um Risiken mit einer hohen Eintrittswahrscheinlichkeit und mäßiger Schadenswirkung [25, 24]. Disruptive Risiken hingegen sind unvorhergesehene Störungen. Sie sind durch Natur oder von Menschen verursachte Katastrophen und zeigen sich in Form von Überschwemmungen, Erdbeben, Terroranschlägen, Pandemien oder durch Wirtschaftskrisen [26]. Diese Störungsrisiken weisen eine geringe Eintrittshäufigkeit auf, aber haben eine hohe und zeitnahe Schadenswirkung auf das gesamte Supply Chain Netzwerk [24].
Die nachfolgende Abbildung demonstriert die Auswirkung der unterschiedlichen Risiken in der Supply Chain. Der Ripple-Effekt unterscheidet sich vom Bullwhip-Effekt dadurch, dass die Störung nicht lokal bleibt oder auf einen Teil der Supply Chain beschränkt wird, sondern ein Ereignis zum anderen führt und die Leistung der gesamten Supply Chain erheblich beeinträchtigt wird. Der Bullwhip-Effekt hingegen zeichnet sich durch kleinere, operative Abweichungen aus [22].
![Abbildung 4: Unterschied zwischen operativen und disruptiven Risiken (Quelle: [22], eigene Darstellung)](/storage/app/media/uploaded-files/Bild4.png)
Abbildung 4: Unterschied zwischen operativen und disruptiven Risiken (Quelle: [22], eigene Darstellung)
Buffering und Bridging
Zwei Strategien zur Minderung oder Vermeidung von Kaskadeneffekten (operatives Risiko) sind beispielsweise „Buffering“ und „Bridging“. Auf der einen Seite hat die Buffering-Strategie einen, nach innen gerichteten, Fokus, indem interne Strukturen geschaffen werden, die das Unternehmen vor der Umwelt schützen und isolieren. Auf der anderen Seite hat die Bridging-Strategie einen externen Fokus, wodurch grenzübergreifende Verbindungen zur Umwelt geschaffen werden. Ein Buffering-Beispiel wäre der Ausbau des Lagers für höhere Bestände, um Lieferengpässe auszugleichen. Eine Bridging-Strategie könnten Beziehungen zu Netzwerkpartnern auf einer kooperativen Basis sein (z.B. Informationsaustausch), um möglicherweise früher von Lieferproblemen zu erfahren. [27]
Bullwhip-Effekt vs. Ripple-Effekt
Der Bullwhip-Effekt ist ein anschauliches Beispiel, wie Dynamiken in Supply Chain Netzwerken aussehen können. Betrachtet man die Kette eines Produktes vom Rohstofflieferanten bis zum Endkunden, in der die Betriebe jeder Stufe beim jeweiligen Lieferanten (Upstream = in Richtung Rohstoff) bestellen und dem jeweiligen Kunden (Downstream = in Richtung Endkunde) liefern, so kann man folgende Beobachtung machen: Eine Änderung der Bestellmenge seitens des Endkunden führt zu immer größer werdenden Änderungen der Bestellmengen Upstream. Dem Rohstofflieferanten, der lediglich die Bestellmengen der direkten Kunden (eine Stufe Downstream) erfährt, wird durch die stark schwankenden Bestellmengen die Planbarkeit derselben erschwert, was oft zu Mehrkosten verschiedenster Art führt. [28] Um dem Bullwhip-Effekt gegenzusteuern muss Information über Angebot und Nachfrage stufenübergreifend ausgebaut werden.

Abbildung 5: Graphische Beschreibung des Bullwhip-Effekts
Störungen in Wertschöpfungsnetzwerken können unterteilt werden in häufige Ereignisse mit geringer Auswirkung und seltene mit großer Auswirkung. Der Bullwhip-Effekt beschreibt eher häufige Ereignisse mit geringer Auswirkung und bezieht sich meist auf Nachfrage- oder Durchlaufzeitänderungen. Seltene Ereignisse mit großer Auswirkung stellen ein jüngeres Forschungsfeld dar, in dem auch der Begriff Resilienz mittlerweile sehr bekannt ist. In der Forschung wird für solche Störungen der sogenannte Ripple-Effekt (Welleneffekt) untersucht, der grob gesagt, die Ausbreitung von Störungen in andere Stufen des Netzwerkes beschreibt [29]. Die nachfolgende Abbildung zeigt die Ausbreitung einer Störung, die in einem Knoten auftritt und in den jeweils nachgelagerten Knoten ebenfalls Störungen auslöst. In der Literatur wird auch oft der Begriff Kaskadeneffekte verwendet, der die Stufenförmige Struktur von Wertschöpfungsnetzwerken unterstreicht [30].
![Abbildung 6: Graphische Beschreibung des Ripple-Effekts (Quelle: [29])](/storage/app/media/uploaded-files/Bild6.jpg)
Abbildung 6: Graphische Beschreibung des Ripple-Effekts (Quelle: [29])
Bottlenecks
In der Praxis ist es wichtig, die Ressourcen für die jeweiligen Prozesse zu berücksichtigen. Zum Beispiel hat jedes Produktionswerk eine bestimmte Kapazität, die nicht überschritten werden kann. Die bestehenden Maschinen, das Personal, usw. stellen Ressourcen dar, die zur Produktion benötigt werden. Maßnahmen, wie Aufstockung des Personals oder Ankauf weiterer Maschinen, benötigen genügend Vorlaufzeit und sind nicht immer unbegrenzt möglich. Wird die Kapazität für einen kurzen Zeitraum überschritten, kommt es zur Bildung bzw. Vergrößerung einer Warteschlange – die Wartezeiten der Aufträge werden hoher. In der Warteschlangentheorie werden neben einfachen Warteschlangen auch ganze Netzwerke betrachtet, deren Knoten Warteschlangensysteme sind. Unter gewissen Voraussetzungen können mittels Fluss-Erhaltungssätzen Engpässe (Bottlenecks) im Netzwerk gefunden werden [31]. Bekannt sind Erhaltungssätze aus der Physik (z.B. Energieerhaltungssatz), wo man sich für Dynamiken physikalischer Größen interessiert. Im Fall von Wertschöpfungsnetzwerken geht es um Flüsse, wobei der Fluss in einen Knoten gleich dem Fluss heraus aus einem Knoten sein muss. Braucht man einfach gesagt vier Reifen, um ein Auto zu produzieren, so muss der Materialfluss an Reifen in die Produktion viermal so hoch sein wie der Produktfluss aus der Produktion.
Mechanismen von Warteschlangen können auch mittels Simulationsmethoden gut nachgebaut werden, was es ermöglicht, verschiedenste Gegebenheiten zu analysieren, ohne dass diese in der Realität existieren. Durch die Rechenleistung moderner Computer, können die meisten üblichen Bürocomputer bereits interessante Simulationen berechnen.
Stufe 4: Performance
Supply Chain Performance
Supply Chain Performance hängt von der Netzwerkstruktur ab (Stufe 2 des Projektes) und wird von den Dynamiken in der Supply Chain (Stufe 3) beeinflusst. Der Begriff bezieht sich auf die Aktivitäten der erweiterten Lieferkette bei der Erfüllung der Anforderungen der Endkunden, einschließlich der Produktverfügbarkeit, der pünktlichen Lieferung und aller erforderlichen Bestände und Kapazitäten in der Lieferkette, um diese Leistung schnell erbringen zu können. Für die kontinuierliche Leistungsüberwachung werden Leistungsmessgrößen oder "Metriken" benötigt. Supply Chain Management umfasst viele Funktionen in einem Unternehmen, weshalb es entscheidend ist, die Leistungsmessgrößen für jedes Unternehmen individuell zu definieren. Gute Leistung an einer Stelle der Supply Chain reicht allerdings nicht aus, um erfolgreich zu sein, weshalb die Leistung des gesamten Supply Chain Netzwerks gemessen und nach dem übergeordneten Ziel ausgerichtet werden sollte. [32]
Supply Chain Performance Kennzahlen dienen als Indikator dafür, wie gut das Supply Chain System funktioniert. Die Messung der Supply Chain Performance kann ein besseres Verständnis der Supply Chain erleichtern und ihre Gesamtleistung verbessern. Es gibt verschiedene Sichtweisen, in welche die Kennzahlen eingeteilt werden können [33]:
- Kosten- und Nichtkostenperspektive
- strategische, taktische oder operative Perspektive
- finanzielle und nicht-finanzielle Perspektive
Eine weitere typische Unterscheidung erfolgt in qualitative und quantitative Kennzahlen [34]:
- Qualitative Kennzahlen, z.B. on-time Lieferung, Flexibilität, Kundenzufriedenheit, usw.
- Quantitative Kennzahlen, z.B. Erfüllungsratemaximierung
Folgende Dimensionen werden unterschieden, wobei die Produktqualität als gegeben vorausgesetzt wird:
- Service, z.B. Pünktlichkeit
- Vermögenswerte, z.B. Bestand
- Schnelligkeit/Flexibilität, z.B. Reaktionsfähigkeit
Key Performance Indicators (KPI)
Supply Chain Performance ist ein Feld, in dem es eine Vielzahl von Indikatoren, sogenannte Key Performance Indices (KPIs), gibt. Diese Indikatoren bzw. Metriken können von jedem Unternehmen individuell festgelegt werden. Zunächst sollten die Ziele des Unternehmens definiert und anschließend geeignete Indikatoren abgeleitet werden. Um die Entwicklung des Unternehmens anhand der Kennzahlen verfolgen zu können, sollten diese regelmäßig und anhand der gleichen Methode erhoben werden. Zudem ist Performance-Measurement ein Bereich, der sich, obwohl Kennzahlen regelmäßig auf die gleiche Art und Weise gemessen werden sollen, ständig weiterentwickelt. Beispielsweise wenn das Unternehmen beschließt, CO2-Emissionen zu messen, werden bestehende Kennzahlensysteme erweitert. Einige Beispiele für KPIs werden nachfolgend beschrieben.
Service Metriken
Es soll gemessen werden, wie hoch die Qualität des Kundenservices ist. Dabei wird zwischen den Produktionsarten Build-to-Order, Build-to-Stock unterschieden. [32]
Build-to-Stock: Die Kunden erwarten, dass diese Artikel sofort und kurzfristig verfügbar sind und die Lieferkette muss Lagerbestände aufweisen. Die wichtigen Metriken hierfür sind: [32]
- Erfüllungsrate von Einzelposten: der Prozentsatz der einzelnen "Zeilen" bei allen Kundenaufträgen, die sofort ausgeführt werden
- Erfüllungsrate von Aufträgen: es werden die Kundenaufträge als Erfolg gezählt, bei denen alle "Zeilen" ausgeführt wurden
Build-to-Order: die Kundenreaktionszeit ist wichtig, da Produkte für den kundenspezifischen Auftrag hergestellt werden. Die wichtigste Metrik in diesem Bereich ist die Standard Lieferzeit (inklusive Auslieferung). Ziel ist es diese Zeit gering zu halten, um wettbewerbsfähig zu sein [32]. Der Lieferservicegrad ist ebenfalls eine wichtige Kennzahl für die Messung der Performance. Der Lieferservicegrad entspricht der Rechnung laut [35]:
Lieferservicegrad (%) = (Auftragsgerechte Auslieferpositionen * 100) / Auslieferpositionen insgesamt
Metriken für Vermögenswerte
Der bedeutendste Vermögenswert in den Lieferketten ist der Bestand in der gesamten Kette. Dafür werden oft die folgenden Metriken berechnet: [32]
- Geldwert: bezieht sich auf das Inventar als Vermögenswert in der Bilanz des Unternehmens
- Lieferzeit oder Lagerumschlag: beziehen sich auf die Materialströme
Für die Betrachtung der Messgrößen Bestand und Service im gesamten Supply Chain Netzwerk sollen alle Investitionen in Bestände entlang der Kette summiert werden und der Service für den Endkunden berechnet werden. Folgende Abbildung zeigt den Unterschied zwischen der Performance in einer Produktionsanlage und der Performance der gesamten Lieferkette. Bei der Betrachtung der gesamten Lieferkette ist zu erkennen, dass die Lieferkette eines Unternehmens bei gleichem Serviceniveau höhere Bestände aufweist als die des Wettbewerbs. Eine solche Analyse weist auf die Notwendigkeit hin, die Partner der Kette dabei zu unterstützen, ihre Aktivitäten effektiver und effizienter durchzuführen, um hohe Bestände zu vermeiden. Auf der anderen Seite kann eine solche Analyse auf Probleme in der eigenen Produktionsstätte hinweisen. [32]
![Abbildung 7: Gegenüberstellung der Lieferkettenansicht (Quelle: [32])](/storage/app/media/uploaded-files/Bild7.png)
Abbildung 7: Gegenüberstellung der Lieferkettenansicht (Quelle: [32])
Beispiele aus der Wissenschaft
Es existieren zahlreiche Methoden zur Messung der Supply Chain Performance. Die Autoren [36] modellieren und berechnen mit Hilfe von Bestandswarteschlangenmodellen die Performance des gesamten Supply Chain Netzwerks. Es werden Indikatoren verwendet, wie beispielsweise die erwartete Anzahl von Bestellungen, die in der Warteschlange stehen oder der erwartete Lagerbestand und die Wahrscheinlichkeit, dass ein Standort im Netzwerk keine Bestände mehr hat.
Ein anderes Beispiel findet sich im Paper [37]. Es werden die Supply Chain Netzwerke als stochastische Petri Netze modelliert und analysiert. Dabei werden Metriken wie die durchschnittlichen Fertigwarenbestände, die Vorlaufzeiten für die Auftragslieferung oder die Materialauffüllungs-Zykluszeiten betrachtet.
In [34] wird die Performance des Supply Chain Netzwerks mit dem Index „Kostenfaktor“ bewertet. Dabei wird zwischen Produktionskosten, Unterbrechungskosten, Koordinierungskosten und Gefährdungskosten unterschieden. Das Ergebnis dieser Methode ist, dass je mehr Knoten pro Stufe vorhanden sind, desto höher sind alle vier klassifizierten Kosten.
Nachhaltigkeit in Wertschöpfungsnetzwerken
Nachhaltigkeit ist ein wichtiges Thema geworden. Dabei wird oft auf eine Reduktion der CO2-Emissionen hingearbeitet. Jedoch muss dabei beachtet werden, dass der Umweltschaden nicht nur verschoben, sondern tatsächlich reduziert wird. Beispielsweise emittieren batteriebetriebene Fahrzeuge weniger CO2 während ihrer Lebensdauer – bei deren Produktion wird aber einerseits mehr CO2 freigesetzt als bei der Produktion von Fahrzeugen mit Verbrennungsmotoren und andererseits werden dabei Rohstoffe benötigt, deren Abbau und Aufbereitung als sehr umweltschädlich gilt.
In der Literatur findet man die sogenannte „Tripple-Bottom-Line“ der Nachhaltigkeit, in der es um folgende drei Aspekte geht: ökologische, ökonomische und soziale Nachhaltigkeit [38]. Für Unternehmen ist dieses Thema daher keineswegs neu, da ökonomische Nachhaltigkeit ein Grundpfeiler der Wirtschaft ist. Um auch die anderen Aspekte der Nachhaltigkeit in das Supply Chain Management zu integrieren (vor allem ökologische Nachhaltigkeit), sollte einerseits der Einfluss von Änderungen in der Umwelt auf das Unternehmen untersucht werden. Andererseits sollte vom Management ein besseres Verständnis der Einflüsse eigener Produkte, Dienstleistungen und Prozesse auf die Umwelt angestrebt werden [39]. Unternehmensstrategien zur Nachhaltigkeit und wie diese in eine bestehende Unternehmensstrategie eingefügt werden können spielen dabei eine wichtige Rolle [40]. Dabei gibt es unterschiedliche Nachhaltigkeitsstrategien, zum Beispiel:
- Introvertiert – Risikovermeidung (Berücksichtigung von externen Standards, um den Ruf des Unternehmens nicht zu schädigen)
- Extrovertiert – Legitimierung (Aktive Veränderung der Gegebenheiten am Markt)
- Konservativ – Effizienzsteigerung (Ökoeffizienz und saubere Produktion)
- Visionär – ganzheitliche Sichtweise
Sustainable Development Goals
Seit 2015 gibt es mit den 17 „Sustainable Development Goals“ (SDGs) der Vereinten Nationen einen Plan für Frieden und Wohlstand auf unserem Planeten (https://sdgs.un.org/goals). Dabei spielt auch Industrie, Innovation und Infrastruktur (Goal Nr.9) eine Rolle. Ziel ist „Aufbau einer widerstandsfähigen Infrastruktur, Förderung einer inklusiven und nachhaltigen Industrialisierung und Förderung von Innovationen“. Dabei ist es ein erklärtes Ziel bis 2030 die Infrastruktur aufzurüsten und die Industrien umzurüsten, um sie nachhaltig zu machen (Target 9.4). Dies soll mit erhöhter Ressourceneffizienz und größerer Übernahme von sauberen und umweltfreundlichen Technologien und industriellen Prozessen gelingen, wobei alle Länder entsprechend ihrer jeweiligen Möglichkeiten Maßnahmen ergreifen sollen. Als Indikator für die Erreichung des Zieles ist die Menge an CO2-Emission pro Wertschöpfungseinheit definiert.
CO2 Reduktion
Der CO2-Ausstoß, der durch das Wertschöpfungsnetzwerk verursacht wird, stellt eine wichtige Größe dar, obwohl Nachhaltigkeit ein wesentlich umfassenderes Konzept ist. Die Berechnung der Emissionsdaten eines gesamten Supply Chain Netzwerks kann mit Hilfe eines Online-Rechners (z.B. https://www.ecotransit.org/de/) durchgeführt werden. Ein bedeutender erster Schritt kann es aber auch sein, Transportkilometer zu reduzieren, indem Optimierungspotentiale realisiert werden oder Kooperationen eingegangen werden. Dabei sollten nicht nur vertikale Kooperationen in Betracht gezogen werden, sondern auch horizontale [41]. Im äußersten Fall könnte man Transportkapazitäten mit den direkten Konkurrenten der Branche teilen, um Ressourcen einzusparen. Auf dem Weg zum Physical Internet, setzt die EU auf Innovation durch Kollaboration, wie die European Technology Plattform ALICE zeigt (http://www.etp-logistics.eu/).
Stufe 5: Optimierung
Netzwerkoptimierung
Das Design von Lieferkettennetzwerken - oder die Netzwerkoptimierung, wie es oft genannt wird - kann als ein Prozess definiert werden, der eine vollständige Sicht auf die Lieferkette des Unternehmens erstellt. Dies beinhaltet in der Regel die Erstellung einer Art Modell, das die Lieferkette zusammen mit geeigneten Formeln, die tatsächliche Transaktionen und Transformationen emulieren, nachbildet. Anhand dieses Modells ist es möglich, verschiedene Aspekte der Lieferkette zu bewerten und Möglichkeiten zur Optimierung der Prozesse und zur Senkung der Lieferkettenkosten zu identifizieren.
Je nach Komplexität der Organisation kann dies den Einsatz von fortschrittlicher mathematischer und analytischer Supply-Chain-Netzwerksoftware erfordern, um Alternativen zu bewerten und optimale Lösungen zu ermitteln.
Einige Beispiele für Supply-Chain-Planungsprozesse mit einer räumlichen Komponente sind [42]:
- Strategische Planung: Standortwahl für Anlagen, Transport- und Distributionsnetzplanung
- Taktische Planung: Bedarfsprognose, Entwurf von Distributionsgebieten auf der letzten Meile, Vorausschauende Instandhaltung
- Operative Planung: Routenplanung
Es gibt verschiedene Methoden, um die oben genannten Beispiele zu implementieren, wie z.B. Dynamic Route Optimization oder Vorhersage von Zeitreihen.
Viele Supply-Chain-Daten können in Form von Zeitreihen dargestellt werden, z. B. Versand- und Logistik- oder Nachfragedaten. Eine Zeitreihenanalyse oder insbesondere eine Zeitreihenvorhersage kann verwendet werden, um die Leistung des Supply-Chain-Netzwerks zu verbessern.
Eine Zeitreihe ist ein Datensatz, der zu aufeinanderfolgenden, diskreten Zeitpunkten gesammelt wird. In der Literatur sind verschiedene Arten von Zeitreihen genannt: diskrete und univariate Zeitreihen, kontinuierliche Zeitreihen oder multivariate Zeitreihen. Im Gegensatz zu univariaten Zeitreihen hängt jede Variable einer multivariaten Zeitreihe nicht nur von ihren vorherigen Werten ab, sondern auch von einigen anderen Variablen. In einer diskreten Zeitreihe werden die Beobachtungen zu diskreten Zeitpunkten gemacht, während sie in einer kontinuierlichen Zeitreihe kontinuierlich über die Zeit gemacht werden.
Eine Zeitreihe kann mit klassischer Zerlegung mit drei Komponenten beschrieben werden [43]:
- Trend: eine langfristige Bewegung im Mittel
- Saisonaler Effekt: Zyklische Schwankungen in Bezug auf den Kalender oder den Konjunkturzyklus
- Restlicher oder genannter mikroskopischer Teil: andere zufällige oder systematische Schwankungen
Die Idee der Zeitreihenbeschreibung besteht darin, Modelle für diese drei Komponenten zu erstellen und diese entweder additiv oder multiplikativ zu kombinieren.
Es ist wichtig zu wissen, dass die additive Zerlegung nützlich ist, um Zeitreihen mit konstanter saisonaler Variation zu beschreiben, während die multiplikative Zerlegung für Zeitreihen mit zunehmender Amplitude des saisonalen Effekts verwendet werden kann.
Die Vorhersage von Zeitreihen ist eine der an den häufigsten angewandten datenwissenschaftlichen Techniken. Sie verwendet ein numerisches Modell, um die zukünftigen Werte einer Zeitreihe auf der Grundlage ihrer zuvor beobachteten Werte vorherzusagen. Zu den bekanntesten Zeitreihen-Vorhersagemodellen gehören [44]:
- Einfaches und doppelt gleitendes Durchschnittsmodell (Simple und Double Moving Average Modell SMA, DMA)
- Einfaches, doppeltes und dreifaches exponentielles Glättungsmodell (Simple, Double und Triple Exponential Smoothing Modell)
- Moving Average (MA) Modell
- Autoregressive (AR) Modell
- ARMA-Modell (Autoregressive Moving Average)
- ARIMA-Modell (Autoregressive Integrated Moving Average)
- Künstliche neurale Netzwerke:
- Deep Neural Network (DNN)
- Long Short-Term Memory (LSTM)
- Gated Recurrent Unit (GRU)
Zeitreihenanalyse wird bei vielen Problemen der Netzwerkoptimierung verwendet. Zwei der bekanntesten Probleme sind Bedarfsprognose und vorausschauende Instandhaltung.
Bedarfsprognose (Demand Forecasting)
Die folgende Abbildung veranschaulicht den Anteil der befragten Versorgungsunternehmen, die vor drei Jahren weltweit digitale Versorgungsanwendungen implementiert haben. Sie zeigt, dass 41 Prozent der Befragten angaben, dass ihre Organisation eine Bedarfsprognose implementiert hat, und 40 Prozent bestätigten die Implementierung von vorausschauender Wartung [44].
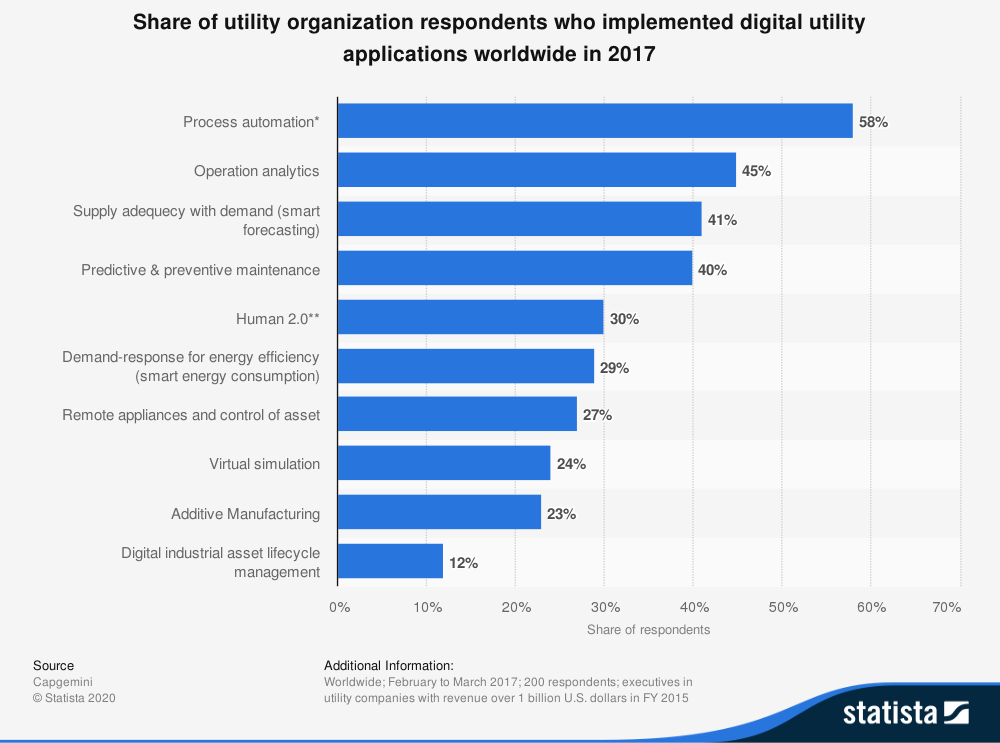
Abbildung 8: Anteil der befragten Versorgungsunternehmen, die im Jahr 2017 weltweit digitale Versorgungsanwendungen implementiert haben (Quelle: Statista)
Für ein Unternehmen, egal ob Hersteller, Großhändler oder Einzelhändler, ist die Nachfragevorhersage ein geschäftskritischer Prozess. Fehler können drastische Folgen haben. Wenn zum Beispiel zu viel Betriebskapital im Bestand gebunden ist, kann es zu Cashflow-Problemen kommen. Ein zu geringer Lagerbestand kann unter differenten Umständen zu Out-of-Stock-Situationen, unzufriedenen Kunden und einem beschädigten Ruf führen.
Die Bedarfsprognose ist der sinnvolle Ausgangspunkt für alle unternehmerischen Planungsaktivitäten, einschließlich des Einkaufs von Artikeln oder der Auffüllung von Beständen. Wenn ein Unternehmen die zukünftige Nachfrage genau vorhersagen kann, kann es seine Bestandsbeschaffungsprozesse optimieren und die Lieferkosten senken, was sich letztlich auf das Endergebnis auswirkt. Die konkreten Vorteile einer Nachfragevorhersage für Unternehmen sind die Verbesserung der Ketteneffizienz, eine bessere Marketingstrategie, eine genauere Budgetierung, ein angemessener Bestand und eine bessere Verfolgung der Gesamtleistung.
Die untenstehende Abbildung visualisiert die Anwendung von maschinellem Lernen in der Einzelhandelsbranche weltweit im Jahr 2019. Maschinelles Lernen ist das Teilgebiet der künstlichen Intelligenz, das "Computern die Fähigkeit verleiht, zu lernen, ohne explizit programmiert zu werden". Während des Befragungszeitraums haben 37 Prozent der Befragten maschinelles Lernen für die Nachfragevorhersage in ihren Unternehmen eingesetzt, und 33 Prozent bestätigten, dass sie es in Zukunft einsetzen würden [44].
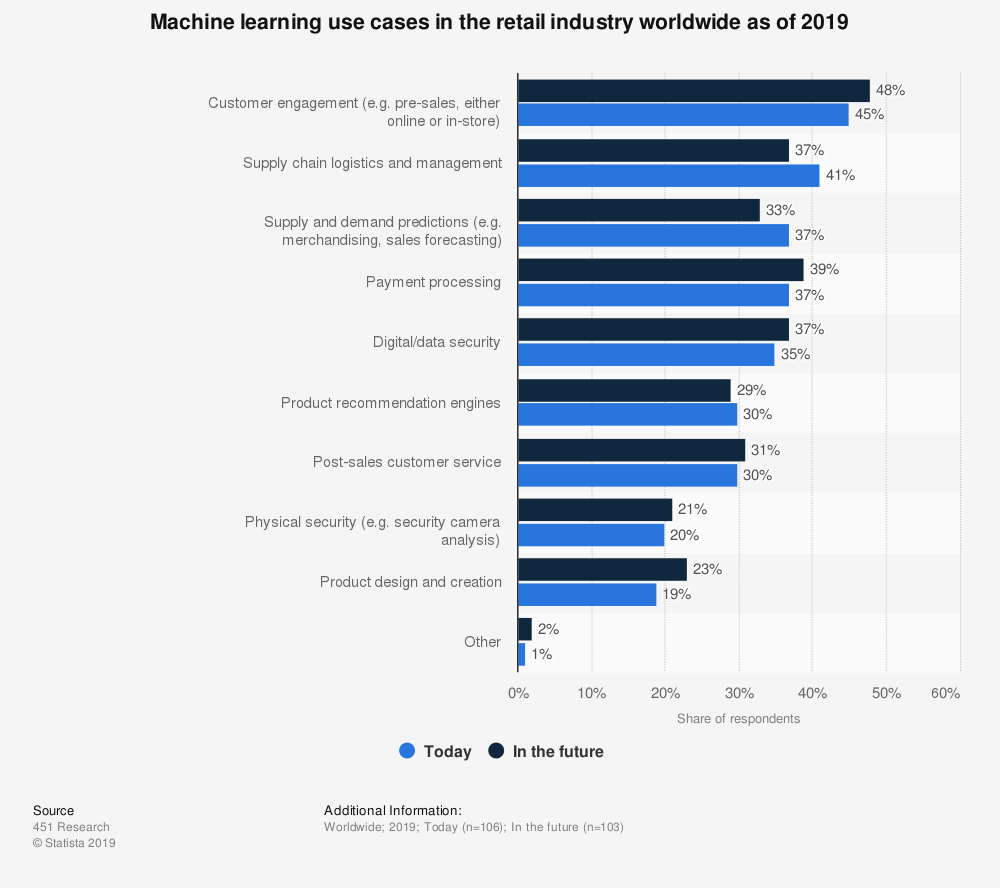
Abbildung 9: Anwendungsfälle von Machine-Learning in der Einzelhandelsindustrie weltweit im Jahr 2019 (Quelle: Statista)
Vorausschauende Instandhaltung (Predictive Maintenance)
Die vorausschauende Instandhaltung ist eine neue Wartungsstrategie, die von vielen Sektoren übernommen wurde, insbesondere in Bereichen, in denen die Zuverlässigkeit von entscheidender Bedeutung ist, wie z. B. in Kraftwerken, Versorgungsunternehmen, Transportsystemen, Kommunikationssystemen und Notdiensten. Im Wesentlichen identifiziert sie Systemausfälle und Fehlfunktionen, um den Wartungsaufwand zu optimieren, indem sie den Zustand des Systems bewertet und die historischen Daten des Systems zur Optimierung des Wartungsaufwands nutzt. Predictive Maintenance-Programme können frühe Anzeichen von Ausfällen oder Fehlfunktionen leicht erkennen und Wartungsmaßnahmen zum richtigen Zeitpunkt einleiten, und Predictive Maintenance-Daten liefern sowohl diagnostische als auch vorausschauende Informationen.
Die Geschichte der vorausschauenden Wartung ist alt. Früher patrouillierten erfahrene Wartungsmitarbeiter auf dem Gelände und setzten alle ihre Sinne (Sehen, Hören, Riechen und Berühren) ein, um Probleme frühzeitig zu erkennen. Dieses Verfahren ist in vielen Fällen immer noch weit verbreitet. Diese alte Methode hat sich durch die Verwendung von Sensoren zur heutigen vorausschauenden Wartung weiterentwickelt. Sensoren übernehmen jetzt die Aufgaben "Sehen, Hören, Riechen und Tasten" und das Konzept der Zustandsbewertung wurde von der Komponenten- oder Maschinenebene auf die Systemebene weiterentwickelt.
In ihrer am stärksten integrierten Form sammelt die vorausschauende Wartung Daten über den Zustand des Systems hauptsächlich durch Sensoren (zunehmend unter Verwendung drahtloser Netzwerksysteme), wertet die Daten aus, bestimmt, wann eingegriffen werden muss, mobilisiert Personal, bestellt Ersatzteile und so weiter. Die nachfolgenden Wartungsmaßnahmen werden aktiviert und umgesetzt. Die vorausschauende Instandhaltung erfordert also einen vielschichtigen Ansatz, der technische und ergonomische Methoden einschließt.
PricewaterhouseCoopers (PCW) [45], ein internationales Expertennetzwerk von Firmen mit Hauptsitz in London, hat 268 Unternehmen in Belgien, Deutschland und den Niederlanden befragt, um herauszufinden, wo sie aktuell in Bezug auf vorbeugende Instandhaltung stehen, was sich seit der letzten Studie im Jahr 2017 geändert hat und welche Pläne die Unternehmen für die nahe Zukunft haben. Es scheint, dass Predictive Maintenance durch Datenanalyse nicht nur ein Modethema für die frühen Phasen des "Hype Cycle" ist. Vielmehr erweist es sich als eine überzeugende neue Technologie, die den Unternehmen, die sie bereits in ihre Instandhaltungsabläufe integriert haben, viele Vorteile bringt. In der Umfrage werden als Vorteile von Predictive Maintenance u.a. genannt die Verbesserung der Betriebszeit, sowie Kostensenkung oder Reduzierung von Sicherheits-, Gesundheits-, Umwelt- und Qualitätsrisiken.
Literatur
1. Biswas, S. und J. Sen. A Proposed Architecture for Big Data Driven Supply Chain Analytics [online]. SSRN Electronic Journal, 2016. Verfügbar unter: doi:10.2139/ssrn.2795906
2. Pipino, L.L., Y.W. Lee und R.Y. Wang. Data quality assessment [online]. Communications of the ACM, 2002, 45(4), 211-218. ISSN 0001-0782. Verfügbar unter: doi:10.1145/505248.506010
3. Laranjeiro, N., S.N. Soydemir und J. Bernardino. A Survey on Data Quality: Classifying Poor Data. In: 2015 IEEE 21st Pacific Rim International Symposium on Dependable Computing (PRDC): IEEE, 18. November 2015 - 20. November 2015, S. 179-188. ISBN 978-1-4673-9376-8.
4. IBM. Supply-Chain-Analysen [online]. Analysen, die Faktoren wie Qualität, Bereitstellung, Kundenerlebnisse und letztlich die Rentabilität beeinflussen können [Zugriff am: 30. Juni 2021]. Verfügbar unter: https://www.ibm.com/de-de/topics/supply-chain-analytics
5. Bowersox, D.J., D.J. Closs und M.B. Cooper. Supply chain logistics management. Internat. ed. Boston: McGraw-Hill, 2002. McGraw-Hill/Irwin series operations and decision sciences. ISBN 0071123067.
6. Hadek, M. Supply Chain Visibility: Identifikation kritischer Lieferanten am Beispiel eines Automobilzuliefernetzwerks. Master thesis. Steyr, 2019.
7. Mitchell, J.C. 2 Networks, norms and institutions. In: J. Boissevain, Hg. Network Analysis: De Gruyter, 1973, S. 15-36. ISBN 9783110877779.
8. Nelson, R.E. Social Network Analysis as Intervention Tool [online]. Group & Organization Studies, 1988, 13(1), 39-58. ISSN 0364-1082. Verfügbar unter: doi:10.1177/105960118801300108
9. Sydow, J. Strategische Netzwerke. Evolution und Organisation. Wiesbaden: Gabler Verlag, 1992. Neue betriebswirtschaftliche Forschung. ISBN 978-3-322-86619-6.
10. Jansen, D. Einführung in die Netzwerkanalyse. Grundlagen, Methoden, Forschungsbeispiele. 2. erweiterte Auflage. Wiesbaden: VS Verlag für Sozialwissenschaften, 2003. ISBN 978-3-663-09875-1.
11. Kim, Y., T.Y. Choi, T. Yan und K. Dooley. Structural investigation of supply networks: A social network analysis approach [online]. Journal of Operations Management, 2011, 29(3), 194-211. ISSN 02726963. Verfügbar unter: doi:10.1016/j.jom.2010.11.001
12. Wasserman, S. und K. Faust. Social Network Analysis: Cambridge University Press, 2012. ISBN 9780521387071.
13. Harland, C.M., R.C. Lamming, J. Zheng und T.E. Johnsen. A Taxonomy of Supply Networks [online]. Journal of Supply Chain Management, 2001, 37(4), 21-27. ISSN 15232409. Verfügbar unter: doi:10.1111/j.1745-493X.2001.tb00109.x
14. Braziotis, C., M. Bourlakis, H. Rogers und J. Tannock. Supply chains and supply networks: distinctions and overlaps [online]. Supply Chain Management: An International Journal, 2013, 18(6), 644-652. ISSN 1359-8546. Verfügbar unter: doi:10.1108/SCM-07-2012-0260
15. BORGATTI, S.P. und X.U.N. LI. On social network analysis in a supply chain context [online]. Journal of Supply Chain Management, 2009, 45(2), 5-22. ISSN 15232409. Verfügbar unter: doi:10.1111/j.1745-493X.2009.03166.x
16. Ahuja, G. Collaboration Networks, Structural Holes, and Innovation: A Longitudinal Study [online]. Administrative Science Quarterly, 2000, 45(3), 425. ISSN 00018392. Verfügbar unter: doi:10.2307/2667105
17. Mizgier, K.J., M.P. Jüttner und S.M. Wagner. Bottleneck identification in supply chain networks [online]. International Journal of Production Research, 2013, 51(5), 1477-1490. ISSN 0020-7543. Verfügbar unter: doi:10.1080/00207543.2012.695878
18. Yan, T., T.Y. Choi, Y. Kim und Y. Yang. A Theory of the Nexus Supplier: A Critical Supplier From A Network Perspective [online]. Journal of Supply Chain Management, 2015, 51(1), 52-66. ISSN 15232409. Verfügbar unter: doi:10.1111/jscm.12070
19. Wichmann, B.K. und L. Kaufmann. Social network analysis in supply chain management research [online]. International Journal of Physical Distribution & Logistics Management, 2016, 46(8), 740-762. ISSN 0960-0035. Verfügbar unter: doi:10.1108/IJPDLM-05-2015-0122
20. Hwarng, H.B. und N. Xie. Understanding supply chain dynamics: A chaos perspective [online]. European Journal of Operational Research, 2008, 184(3), 1163-1178. ISSN 03772217. Verfügbar unter: doi:10.1016/j.ejor.2006.12.014
21. Fiege, S., Hg. Risikomanagement- und Überwachungssystem nach KonTraG. Prozess, Instrumente, Träger. s.l.: DUV Deutscher Universitäts-Verlag, 2006. ISBN 978-3-8350-5704-3.
22. Ivanov, D., A. Tsipoulanidis und J. Schönberger. Global supply chain and operations management. A decision-oriented introduction to the creation of value. Second edition. Cham: Springer, 2019. Springer texts in business and economics. ISBN 978-3-319-94313-8.
23. Wittmann, E. Risikomanagement im internationalen Konzern. In: D. Dörner, Hg. Praxis des Risikomanagements. Grundlagen, Kategorien, branchenspezifische und strukturelle Aspekte. Stuttgart: Schäffer-Poeschel, 2000, 970-820. ISBN 3791014528.
24. Ivanov, D. Predicting the impacts of epidemic outbreaks on global supply chains: A simulation-based analysis on the coronavirus outbreak (COVID-19/SARS-CoV-2) case [online]. Transportation research. Part E, Logistics and transportation review, 2020, 136, 101922. Verfügbar unter: doi:10.1016/j.tre.2020.101922
25. Lücker, F. und R.W. Seifert. Building up Resilience in a Pharmaceutical Supply Chain through Inventory, Dual Sourcing and Agility Capacity [online]. Omega, 2017, 73(1), 114-124. ISSN 03050483. Verfügbar unter: doi:10.1016/j.omega.2017.01.001
26. Tang, C.S. Perspectives in supply chain risk management [online]. International Journal of Production Economics, 2006, 103(2), 451-488. ISSN 09255273. Verfügbar unter: doi:10.1016/j.ijpe.2005.12.006
27. Manhart, P., J.K. Summers und J. Blackhurst. A Meta‐Analytic Review of Supply Chain Risk Management: Assessing Buffering and Bridging Strategies and Firm Performance [online]. Journal of Supply Chain Management, 2020, 56(3), 66-87. ISSN 15232409. Verfügbar unter: doi:10.1111/jscm.12219
28. Lee, H.L., V. Padmanabhan und S. Whang. Information Distortion in a Supply Chain: The Bullwhip Effect. Management Science, 1997, 43(4). ISSN 0025-1909.
29. Ivanov, D. Simulation-based ripple effect modelling in the supply chain [online]. International Journal of Production Research, 2017, 55(7), 2083-2101. ISSN 0020-7543. Verfügbar unter: doi:10.1080/00207543.2016.1275873
30. Ojha, R., A. Ghadge, M.K. Tiwari und U.S. Bititci. Bayesian network modelling for supply chain risk propagation [online]. International Journal of Production Research, 2018, 46(1), 1-25. ISSN 0020-7543 [Zugriff am: 16. Juli 2018]. Verfügbar unter: doi:10.1080/00207543.2018.1467059
31. Armbruster, D., P. Degond und C. Ringhofer. A Model for the Dynamics of large Queuing Networks and Supply Chains [online]. SIAM Journal on Applied Mathematics, 2006, 66(3), 896-920. ISSN 0036-1399. Verfügbar unter: doi:10.1137/040604625
32. Hausman, W.H. Supply Chain Performance Metrics. In: T.P. Harrison, H.L. Lee und J.J. Neale, Hg. The practice of supply chain management. Where theory and application converge. New York: Springer, 2005, S. 61-73. ISBN 0-387-24099-3.
33. Kurien, G. und M.N. Qureshi. Study of performance measurement practices in supply chain management. International Journal of Business, Management and Social Sciences, 2011, 2(4), 19-34.
34. Chen, T. und X. Gong. Performance Evaluation of a Supply Chain Network [online]. Procedia Computer Science, 2013, 17, 1003-1009. ISSN 18770509. Verfügbar unter: doi:10.1016/j.procs.2013.05.127
35. Werner, H. Supply Chain Management. Grundlagen, Strategien, Instrumente und Controlling. 6., aktualisierte und überarbeitete Auflage. Wiesbaden: Springer Gabler, 2017. Lehrbuch. ISBN 978-3-658-18383-7.
36. Dong, M. und F. Frank Chen. Performance modeling and analysis of integrated logistic chains: An analytic framework [online]. European Journal of Operational Research, 2005, 162(1), 83-98. ISSN 03772217. Verfügbar unter: doi:10.1016/j.ejor.2003.10.030
37. Viswanadham, N. und N.R. Srinivasa Raghavan. Performance analysis and design of supply chains: a Petri net approach [online]. Journal of the Operational Research Society, 2000, 51(10), 1158-1169. ISSN 0160-5682. Verfügbar unter: doi:10.1057/palgrave.jors.2600063
38. Elkington, J. Cannibals with forks. The Triple Bottom Line of 21st Century Business. Oxford: Capstone, 1999. ISBN 978-1841120843.
39. Lee, K.-H. und Y. Wu. Integrating sustainability performance measurement into logistics and supply networks: A multi-methodological approach [online]. The British Accounting Review, 2014, 46(4), 361-378. ISSN 08908389. Verfügbar unter: doi:10.1016/j.bar.2014.10.005
40. Baumgartner, R.J. und D. Ebner. Corporate sustainability strategies: sustainability profiles and maturity levels [online]. Sustainable Development, 2010, 18(2), 76-89. ISSN 09680802. Verfügbar unter: doi:10.1002/sd.447
41. Ballot, E. und F. Fontane. Reducing transportation CO 2 emissions through pooling of supply networks: perspectives from a case study in French retail chains [online]. Production Planning & Control, 2010, 21(6), 640-650. ISSN 0953-7287. Verfügbar unter: doi:10.1080/09537287.2010.489276
42. Chopra, S. und P. Meindl. Supply Chain Management. Strategy, Planning & Operation. In: C. Boersch und R. Elschen, Hg. Das Summa Summarum des Management. Wiesbaden: Gabler, 2007, S. 265-275. ISBN 978-3-8349-0519-2.
43. Box, G.E.P., G.M. Jenkins, G.C. Reinsel und G.M. Ljung. Time series analysis: forecasting and control: John Wiley & Sons, 2015.
44. Pham, T.S. A hybrid framework for prediction problem in large collections of short time series, 2020.
45. Haarman, M., M. Mulders und C. Vassiliadis. Predictive Maintenance 4.0 [online]. Predict the unpredictable, 2017 [Zugriff am: 30. Juni 2021]. Verfügbar unter: https://www.pwc.nl/nl/assets/documents/pwc-predictive-maintenance-4-0.pdf